Базовой структурной единицей RDF является коллекция троек (или триплетов), каждый из которых состоит из субъекта, предиката и объекта (S,P,O). Набор триплетов называется RDF-графом. В качестве вершин графа выступают субъекты и объекты, в качестве дуг – предикаты (или свойства). Направление дуги, соответствующей предикату в данной тройке (S,P,O), всегда выбирается так, чтобы дуга вела от субъекта к объекту.
Рис. 17. RDF-тройка.
Каждая тройка представляет некоторое высказывание, увязывающее S, P и O.
Первые два элемента RDF-тройки (Subject, Predicate) идентифицируются при помощи URI.
Объектом может быть как ресурс, имеющий URI, так и RDF-литерал (значение).
RDF-литералы (или символьные константы)
RDF-литералы бывают 2-х видов: типизированные и не типизированные.
Каждый литерал в RDF-графе содержит 1 или 2 именованные компоненты:
Все литералы имеют лексическую (словарную) форму в виде строки символов Unicode.
Простые литералы имеют лексическую форму и необязательную ссылку на язык (ru, en…).
Типизированные литералы имеют лексическую форму и URI типа данных в форме RDF URI.
Замечание . Язык литерала не нужно путать с идентификатором локали. Языка относится только к текстам, написанным на естественном языке. Все трудности, возникающие при представлении данных на конкретном компьютере (при определении локали), должны решаться конечным пользователем.
Сравнение литералов
Два литерала равны тогда и только тогда, когда выполняются все перечисленные ниже условия:
1. Строки обеих лексических форм совпадают посимвольно;
2. Либо оба литерала имеют теги языка, либо оба не имеют;
3. Теги языка, если они имеются, совпадают;
4. Либо оба литерала имеют URI типа данных, либо оба не имеют;
5. При наличии URI типа данных, эти URI совпадают посимвольно.
Определение значения типизированного литерала
Приведем пример:
Пусть множество {T, F} - множество значений истинности в математической логике. В различных приложениях элементы этого множества могут представляться по-разному. В языках программирования {1, 0} (1 соответствует T, 0 соответствует F), либо {true, false}, либо {истина, ложь}.
Фактически задается некоторое отображение множества значений истинности на множество чисел или строк символов. Теперь значениями логического типа (bool или boolean) в становятся строковые значения или спецсимволы. Чтобы получить значения истинности необходимо воспользоваться обратным отображением.
Таким же образом происходит получение значения типизированного RDF литерала. За лексической формой стоит некоторое значение, которое определяется применением отображения. Это отображение определяется по URI типа данных и зависит от самого типа.
Основы языка представления RDFS.
Каждый из элементов триплета определяется независимо ссылкой на тип элемента и URI.
Предикат (в контексте RDF его обычно называют свойством) может пониматься либо как атрибут, либо как бинарное отношение между двумя ресурсами. Но RDF сам по себе не предоставляет никаких механизмов ни для описания атрибутов ресурсов, ни для определения отношений между ними. Для этого предназначен язык RDFS – (язык описания словарей для RDF). RDF Schema определяет классы, свойства и другие ресурсы.

Рис.18. RDF-тройка субъект-предикат-объект
RDFS является семантическим расширением RDF. Он предоставляет механизмы для описания групп связанных ресурсов и отношений между этими ресурсами. Все определения RDFS выражены на RDF (поэтому RDF и называется «самоописывающимся» языком). Новые термины, вводимые RDFS, такие как «домен», «диапазон» свойства, являются ресурсами RDF.
Resource Description Framework (RDF) является стандартом W3C для описания сетевых ресурсов, таких как заголовок страницы, автору, дате изменения, содержание и информацию об авторских правах.
Вы должны иметь базовые знания
Прежде чем продолжить, вы должны иметь базовые знания о следующем понимании:
- XHTML
- Пространства имен XML
Если вы хотите изучать эти предметы во- первых, пожалуйста, посетите наш домашнюю страницу .
Что такое RDF?
- RDF относится к Resource Description Framework (Resource Description Framework)
- RDF является описание ресурса рамки для Web
- RDF предоставляет модель и грамматику для таких независимых групп, которые могут обмениваться данными и использовать его
- RDF предназначен для чтения и понимания компьютером
- Цель RDF предназначен не появляться людям
- RDF использует XML для записи
- RDF является неотъемлемой частью W3C Semantic Web Activity
- RDF является рекомендацией W3C
RDF - Примеры применения
- Описание недвижимости торговые пункты, такие как цена и доступность
- Описание графика Веб-событие
- Для описания информации страницы, такие как содержание, автора и дату создания или изменения
- Фотографии и описание рейтинга содержимого сети
- Описание для поисковых систем
- Описание Электронная библиотека
RDF предназначен для чтения с помощью компьютера
РДФ призвана обеспечить общий способ описания информации таким образом, чтобы его можно было прочитать с помощью компьютерной применения и понимания.
Описание RDF не предназначен для отображения в сети.
RDF использует XML для записи
RDF документы написаны в XML. язык XML используется RDF называется RDF / XML.
Используя XML, информация RDF легко могут быть обменены между операционной системой и компьютером используются различные типы языков приложений.
RDF и семантический веб
RDF язык является неотъемлемой частью W3C Semantic Web Activity. Консорциума W3C "Semantic Web Vision (Semantic Web Vision)" Цели:
- Веб-информация имеет точное значение
- Веб-информация может быть понята компьютером и обрабатываются
- Компьютеры могут интегрировать информацию из Интернета
RDF является стандартом W3C
РДФ в феврале 2004 года стали стандарты W3C.
Реляционная модель, десятилетиями служившая основой технологии работы с данными, более не является главенствующей - на сцену выходят новые задачи, требующие учета и выявления существенно большего количества взаимосвязей. Среди новых методов - модель RDF.
14.11.2012 Владислав Головков, Андрей Портнов, Виктор Чернов
Реляционная модель, десятилетиями служившая основой технологии работы с данными, более не является главенствующей - на сцену выходят новые задачи, требующие учета и выявления существенно большего количества взаимосвязей. Среди новых методов обработки данных выделяется модель RDF: переход от баз данных SQL к системам RDF обещает технологический скачок, сравнимый с переходом от Кобола к SQL.
До сих пор наиболее распространенной моделью хранения данных была реляционная, которая с конца 70-х годов и поныне является стандартом де-факто на хранение структурированных данных, а язык SQL - стандартом на их обработку. Однако доля структурированных данных становится все меньше, и реляционная модель испытывает все больше проблем при работе со значительными объемами данных - давно, например, была замечена деградация производительности реляционных СУБД при решении задач аналитической обработки, характерными чертами которых являются «длинные» SQL-запросы, работающие с несколькими таблицами при наличии большого числа агрегатов.
Сегодня задачи, выходящие за рамки реляционной модели, принято относить к классу NoSQL, каждый подкласс которого решает ту или иную проблему, плохо реализуемую с помощью SQL, - например, базы данных с поколоночным хранением, документо-ориентированные, графовые, базы данных ключ-значение и объектные. Скажем, базы данных ключ-значение применяются для задач, характеризующихся чрезвычайно большими объемами, отсутствием операций join и ограниченными требованиями к обновлению данных (например, только добавление). В силу своего объема такие базы заведомо распределенные, что, в свою очередь, означает полный отказ от транзакций - такая упрощенная модель данных дает новые возможности повышения производительности за счет широкого использования параллельных архитектур.
Еще один класс задач, трудно решаемых на реляционной модели, - это задачи на сильно связанных данных или графовые задачи. Попытки решения таких задач на реляционной модели приводят к непредсказуемому количеству соединений в запросах, поэтому для решения графовых задач сегодня наибольшее распространение получили RDF-хранилища, главным достоинством которых является наличие хорошо проработанных стандартов комитета W3C на язык описания графов (Resource Description Framework, RDF) и на обработку графовых данных (SPARQL - рекурсивный акроним: SPARQL Protocol And Rdf Query Language).
Модель RDF возникла в конце 90-х годов, а в 2001 году в журнале Scientific American была опубликована знаменитая статья Тима Бернерса Ли, провозглашающая приход эры семантической паутины (Semantic Web). С той поры в сетевом сообществе стал лавинообразно нарастать интерес ко всему, что связано с семантической обработкой, в том числе и к RDF, который в 2004 году был принят как стандарт комитета W3C.
Основа RDF - это хорошо известное специалистам по искусственному интеллекту представление данных в виде утверждений (троек, triples) субъект-предикат-объект, описывающих направленную связь от субъекта к объекту. Для идентификации субъектов, объектов и предикатов используется идентификатор Uniform Resource Identifier (URI), являющийся обобщением понятия URL. Например:
субъект/объект:
Предикат:
Объекты, кроме URI, могут быть представлены также литералами, например, название журнала: «Journal 1 (1940)»^^xsd:string.
В отличие от реляционной модели, имеющей жесткую структуру, модель RDF достаточно гибкая - каждый субъект может содержать свои собственные предикаты и объекты, например, в единой базе товаров все товары имеют предикат «Цена», но в то же время холодильники могут иметь предикат «Объем морозильной камеры», а телевизоры - предикат «Диагональ экрана».
Наиболее известные форматы представления RDF - текстовые файлы XML, JSON, N-Triples, N3 и Turtle. Например, представление некоторых данных в формате Turtle:
@prefix xsd: . @prefix f: . xsd:type ; f:name «Стандарт специализированной медицинской помощи детям с галактоземией»; f:mkb ; f:service , ; f:drug ; xsd:type ; f:name «Оптиконевромиелит [болезнь Девика]»; xsd:type ; f:name «Общее нейропсихологическое обследование»; xsd:type ; f:name «Актовегин»;
Данный пример представляет фрагмент графа, описывающего стандарт медицинской помощи при заболевании, включая диагноз по классификатору МКБ 10, связанные с ним медицинские услуги и медикаментозное лечение.
Модель RDF по существу описывает ориентированный граф (рис.1), в котором каждая тройка - это описание отношения, то есть связи между двумя узлами.
Язык запросов
Модель RDF служит для описания данных, но не описывает методов их обработки. Существует целый ряд языков запросов к RDF-данным: DQL, N3QL, R-DEVICE, RDFQ, RDQ, RDQL, SeRQL и т. д., но самым популярным стал SPARQL, принятый в качестве стандарта W3C. Язык SPARQL, в отличие от SQL (который критикуют, в частности, за отсутствие кросс-платформности, проблемы с обработкой отсутствующих данных, неоднозначную грамматику и семантику), обладает более стройной структурой и мощью. Основная часть запроса на SPARQL - шаблон, описывающий подграф, который требуется найти в общем графе. Шаблон представляется в виде набора троек с переменными - например, запрос на поиск в некотором графе человека по имени Петр:
Select? x where {? x: тип: человек. ? x: имя «Петр» }
Здесь Блок «select» содержит список переменных для вывода результата запроса; «?x» - это переменная, которая в момент поиска приобретет значение URI найденного объекта. Блок «where» содержит набор троек, составляющих шаблон запроса. В результате поиска будет найден подграф, удовлетворяющий шаблону (рис. 2).
Язык SPARQL прост в освоении для человека, знакомого с SQL, - многое в SPARQL ему покажется известным. Например, в языке присутствуют такие конструкции, как UNION, ORDER BY, GROUP BY, DISTINCT, OFFSET и LIMIT. На сегодняшний день SPARQL является одним из самых выразительных языков обработки данных. Кроме языка запросов, стандарт SPARQL регламентирует протокол взаимодействия с базой данных и формат результата, что является большим шагом вперед по сравнению с SQL.
Вместе с достоинствами модель RDF и язык SPARQL имеют и недостатки. Начнем с достоинств.
Гибкость. Изменения архитектуры информационной системы, построенной на модели RDF, происходят легче, чем для системы, построенной на реляционной модели, и, как правило, даже не требуют реинжиниринга базы.
Современная архитектура. Запросы к хранилищу RDF обычно совершаются с помощью протокола HTTP, благодаря чему они легко встраиваются в сервисные архитектуры без построения промежуточных слоев, потери надежности и производительности. RDF и SPARQL лучше работают с интернациональным контентом, чем базы SQL.
Стандартизация. Уровень стандартизации RDF и SPARQL гораздо выше, чем в SQL, - усилиями комитета W3C определены стандарты не только на модель RDF и язык SPARQL, но и на идентификацию ресурсов (URI), протокол взаимодействия компонентов (HTTP), точку доступа SPARQL и т. д. Благодаря стандартизации, данные, выгруженные из любого RDF-хранилища, можно загружать в RDF-хранилища различных производителей. Запросы на SPARQL одинаково выполняются на разных хранилищах, что высоко ценят разработчики, сталкивающиеся с проблемами переноса данных и запросов из одной базы в другую.
Метаданные. SPARQL позволяет легко отследить происхождение любых единиц данных. В RDF легко хранить самые разные метаданные. На основе метаданных можно делать сложные запросы, выбирая, скажем, данные из конкретных источников, в конкретном временном диапазоне и т. д.
Основным недостатком модели RDF по сравнению с реляционной, пожалуй, является ее «юность». SQL имеет за плечами многолетний инсталляционный и эксплуатационный багаж, в том числе и в критически важных приложениях, - функциональное богатство таких баз пока существенно превосходит RDF. Транзакционный механизм в RDF-хранилищах, как правило, если и реализован, то достаточно грубо.
Инструментарий RDF
Почти все производители реляционных СУБД избегают широкой огласки результатов тестов конфигураций, построенных на том или ином инструментарии SQL, и единственным открытым источником являются тесты TPC для дорогих высокопроизводительных систем, решающих ограниченный класс задач. Мир систем RDF открыт для исследований, экспериментов и тестов - легко можно найти результаты тестов на разных задачах, на компьютерах разной мощности и архитектуры, а главное, подобрать наиболее подходящий для решения конкретной прикладной задачи инструментарий работы с моделью RDF.
Berlin SPARQL Benchmark (BSBM). Тест (www4.wiwiss.fu-berlin.de/bizer/berlinsparqlbenchmark) моделирует данные, связанные с электронной коммерцией, включая товары от разных производителей, отзывы покупателей о товарах и т. д. Данный тест предназначен для оценки скорости выполнения SPARQL-запросов. Модель приближена к реляционной, поэтому есть возможность оценить, насколько эффективна была бы замена базы данных SQL на RDF-хранилище. Модель и запросы теста весьма продуманны и приближены к практике. Возможно, поэтому BSBM - один из наиболее популярных тестов. В опубликованных на сайте разработчиков теста результатах за февраль 2011 года лидером являются такие средства разработки для RDF, как Virtuoso, 4Store, OWLIM и Jena TDB.
SP²Bench SPARQL Performance Benchmark. Тест (dbis.informatik.uni-freiburg.de/index.php?project=SP2B) построен на модели известной библиотеки DBLP литературы по логическому программированию (DataBase systems and Logic Programming): публикации, статьи, журналы, книги и т. д. Так же, как и BSBM, данный тест разработан для оценки скорости выполнения SPARQL-запросов, однако он использует более изощренные запросы, в ущерб их реалистичности. Данный тест хорош для тестирования оптимизатора запросов, поскольку содержит много сложных операций объединения. В опубликованных результатах места распределились следующим образом: Virtuoso, Sesame, ARQ. Недавно проведенное нами сравнительное тестирование сервера RDF NitrosBase Storage на тестах SP2Bench показало его значительное превосходство в производительности перед Virtuoso (от 10 до 10 тысяч раз в зависимости от запроса).
DBpedia SPARQL Benchmark. Тест DBPSB (svn.aksw.org/papers/2011/VLDB_AKSWBenchmark/public.pdf) основан на реальных запросах к базе знаний Dbpedia. Методика разработки теста настолько же оригинальна, насколько целесообразна. Авторы анализируют логи реальных обращений пользователей к базе Dbpedia, кластеризуют их и выделяют наиболее статистически значимые группы запросов, которые затем вносятся в очередную версию теста. Таким образом, DBPSB - это максимально приближенный к жизни тест. Наиболее быстро этот тест выполняет Virtuoso, затем идут OWLIM, Sesame и Jena TDB.
Lehigh University Benchmark. Тест LUBM (swat.cse.lehigh.edu/projects/lubm/) специально разработан для оценки семантических возможностей, поэтому не так распространен, как другие. Основан он на онтологической базе знаний о некотором университете. Известны результаты этого теста, прежде всего, для систем со средствами логического вывода, такими как OWLIM, YarcData, Sesame и др.
Сегодня наблюдается бурный рост рынка средств разработки на основе модели RDF - часть инструментальных средств имеют специализированную архитектуру для обработки графов, часть построены поверх реляционных баз.
Apache Jena - Java API для разработки приложений Semantic Web. Продукт включает в себя несколько хранилищ, собственное хранилище троек (Jena TDB), интерфейс к реляционному хранилищу (Jena SDB), хранилище в памяти (In-Memory), а также средства для поддержки собственных хранилищ. Наиболее сильная сторона Jena - богатый программный интерфейс. Многие RDF-хранилища используют Jena API для доступа к собственным СУБД (IBM, OWLIM и т. д.). Слабой стороной является низкая производительность даже на родном хранилище.
Ontotext OWLIM - семейство семантических репозиториев или RDF СУБД с собственным ядром, реализованным на Java, с поддержкой семантики на RDFS (RDF Scheme) и OWL. Продукт OWLIM активно используется в научно-исследовательских проектах и программных системах. Выпускается в следующих редакциях: OWLIM-Lite для приложений, поддерживающих менее 100 млн троек; OWLIM-SE (ранее BigOWLIM) предназначен для обработки больших объемов данных, с большими потоками запросов; OWLIM-Enterprise (ранее BigOWLIM Replication Cluster) предназначен для построения масштабируемых производительных надежных решений, основанных на параллельной обработке и имеющих средства автоматической защиты от сбоев.
OpenLink Software Virtuoso - обладает собственным мощным RDF-хранилищем, полной реализацией SPARQL, возможностью чтения данных RDF из файлов формата XML и Turtle. Кроме того, поддерживается SPARQL/Update (SPARUL) - расширение SPARQL для поддержки обновления данных. Продукт является одним из лидеров по производительности.
Крупные корпорации, такие как IBM и Oracle, также разрабатывают собственные RDF-решения. Первая встроила в очередную версию СУБД DB2 вариант модели RDF, имеющий название NoSQL Graph Support, с интерфейсом на основе расширения API Jena. Отличается высокой производительностью выполнения RDF-операций. Компания Oracle подключила RDF к своему продукту для работы с пространственными данными - Spatial Data Option, который теперь называется Spatial and Graph Option.
Кроме того, разрабатываются специализированные компьютеры, ориентированные на работу с графовой информацией и поддерживающие модель RDF. Например, в начале 2012 года компания Cray объявила о создании нового высокопроизводительного программно-аппаратного комплекса uRiKA (universal RDF integration Knowledge Appliance), ориентированного на рынок семантических баз данных.
Задачи
После статьи Тима Бернерса Ли в общественном сознании модель RDF стала прочно ассоциироваться с семантической паутиной, однако потенциал этой модели намного выше. Например, большинство задач, решаемых сегодня в рамках реляционной модели, легко можно решать и на RDF. Кроме того, RDF-хранилища позволяют собирать, хранить и индексировать данные из различных источников - в частности, при решении актуальной задачи интеграции сервисов, которая сводится к объединению разрозненных реляционных баз в единую базу и приводит к задаче обработки квазиструктурированных данных. Данные внутри каждой из баз строго структурированы для работы с реляционной моделью, но каждая база структурирована по-своему, поэтому задача их интеграции в рамках реляционной модели требует реинжиниринга всего решения. Если же конвертировать такие базы в модель RDF, то интеграция сведется к простому слиянию RDF-графов и переписыванию запросов из SQL в SPARQL, что не составляет труда в силу гораздо большей выразительности SPARQL по сравнению с SQL.
RDF-хранилища идеально подходят для задач, требующих учета и выявления большого количества взаимосвязей. Кроме наиболее широко анонсируемых задач, связанных с развитием Semantic Web, существует большое количество классических задач, требующих применения графовых подходов:
- обработка семантических сетей (и других графовых структур), полученных в результате анализа текстов (системы специализированного аналитического поиска, системы анализа рынков, маркетинговые исследования, анализ текстов в системах безопасности и др.);
- представление и обработка данных для анализа поведения в социальных сетях (маркетинговые исследования, например построение портрета покупателя; анализ и выявление центров распространения информации в социальных сетях; анализ политических предпочтений);
- анализ и обработка данных о взаимодействии различных модулей и подсистем (включая анализ логов) для систем обеспечения надежности и безопасности больших программно-аппаратных комплексов;
- представление и обработка графов, содержащих разнородную информацию в системах планирования и управления ведением боевых операций;
- обработка данных сложных научных экспериментов;
- медицинские системы нового поколения, особенностью которых является то, что, например, различные услуги требуют различных структур для своего описания, что очень сложно укладывается в строгую реляционную модель. Как только медицинская система начинает учитывать не только сам факт услуги, но и ее детализацию, то сложность системы резко возрастает - например, услуга «осмотр врача» и услуга «клинический анализ» имеют с точки зрения реляционной модели совершенно различную структуру данных, а RDF позволяет обрабатывать такие данные естественным образом, существенно сокращая трудозатраты на развитие и сопровождение подобных систем;
- интеллектуальные адаптивные системы управления производством, имеющие ярко выраженную графовую структуру;
- финансовый анализ, основанный на моделировании и обработке графов, описывающих взаимодействие участников рынка, выявление аффилированных компаний, коррупционный анализ, анализ движения средств структур и т. д.
Практически все задачи, в которых количество взаимосвязей между сущностями превышает количество сущностей или основной целью которых является анализ взаимосвязей, могут рассматриваться как кандидаты на решение средствами систем RDF.
Владислав Головков ([email protected]), Андрей Портнов ([email protected]), Виктор Чернов ([email protected]) - сотрудники компании «Компайл Груп» (Москва).
В этой заметке я попытаюсь объяснить на пальцах ключевые моменты и обосновать преимущества модели RDF.
Более 10 лет концепция Semantic Web, частью который является RDF развивалась, была предметом споров и обсуждений, и сегодня ее все активнее поддерживает сообщество в своих приложениях.
Однако для многих все еще совсем не понятно:
- Зачем все это?
- Как с этим работать?
- Что это даст именно мне?
Большинство, хотя бы мельком, видели знаменитый пирог:

Тут много спецификаций, технологий, концепций - аж глаза разбегаются… Нижний уровень стар как мир, над верхним уровнем бьются академики, пытаясь найти простое и универсальное решение, чтобы научить приложения оценивать, на сколько, можно верить располагаемым утверждениям, полученным из сети. Рядовым разработчикам можно пока не беспокоиться об этом и подождать еще лет 5. Ребята из w3c не покладая рук шлифуют стандарты чуть выше середины, некоторые уже отшлифовав, такие как RDF и для них уже понаписано куча инструментов для всех основных платформ и языков чтобы можно было сразу идти и использовать. Именно с ними все чаще приходится сталкиваться в реальных приложениях, в первую очередь именно с RDF моделью.
Очень хорошо бы еще понимать, зачем нужны, что дают, и как работать с онтологиями – но об этом не в этот раз.
Итак, попробуем разобраться, что мы получаем от использования модели:
- Логический вывод новых фактов
- Обеспечения семантического поиска
- Гибкость модели данных
- Экстремальная легкость обмена данными между системами
Если вы никогда раньше не изучали формальную логику, то пока отложите в памяти, что имея формально описанные факты можно автоматически получить ряд новых фактов, явно не определенных… эта тема заслуживает отдельного внимания, пока ее не трогаем.
Семантический поиск, зачем, ведь есть гугл?
Да можно ввести и вы получете что угодно только не то набор пользователей. Почему? - потому что гугл будет искать нахождение слова из запроса в тексте документов, и возвращать документы а не факты.
А если бы он понял что нам нужны объекты «пользователь» ресурса «хабр», а формальные описания этих объектов были бы доступны для индексирования в модели RDF (например в форме записи RDFa на странице, чтобы поисковая машина могла бы их проиндексировать) был бы получен набор объектов которые мы искали.
Многие возражают – «я могу походить по паре ссылок, сделать еще пару уточняющих запросов и найти все же что нужно, зачем все это?» – ответ – затем что мы не используем бумажные картотеки сегодня, а предпочитаем вбить в строку поиска пару ключевых слов, и само сабой разумеется сразу же получить информацию. На работу мы почему-то ездим на машинах, а на лошадях – потому что это удобнее.
На вопрос – «Как RDF обеспечивает семантический поиск?» - ответ: RDF модель обеспечивает формальные описания. А там где есть формальные описания поисковый агент может искать факты и знания.
Гугл сегодня такое не ищет – зачем мне надо сейчас париться об этом? В первую очередь для получения преимуществ описанных дальше, а во вторых чтобы не «опоздать» - индустрия у нас такая – «be quick or be dead».
Поговорим более подробно о двух других преимуществах, они гораздо проще для понимания, как мне кажется. Но для начала проясним еще пару моментов.
Что такое модель RDF?
Сразу нужно понять RDF – это модель, абстрактная, очень простая, немного в вакууме. Просто направленный граф с несколькими дополнениями и оговорками. А вот записать его можно по разному, обычно выбор падает на один из вариантов: N3,N-Triples, Turtle,RDF/XML,RDFa и используемую спецификацию придется изучить.
Что описывается: С помощью RDF можно описать как документы, отдельные фрагменты знаний внутри документа, так и объекты реального мира, например конкретного живого человека (тут некоторые it-шники впадают в ступор)
.
Идентифицируется все с помощью URI. Притом URI хоть и похож на обычные URL ссылки – немного другое, например можно определить ресурс – реального человека и задать для него URI «http://example.org/people#Вася Пупкин».
Да, можно писать по русски так как юникод а вот что нужно понимать, так то, что это не url – нельзя вставить в браузер и получить человека
- наука до этого еще не дошла.
Попробуем разобраться где-же здесь гибкость модели и обмена данными между системами.
Давайте посмотрим как общаются люди:
Они записывают свои мысли(формализуют) с помощью некого языка множеством способов, письменно, устно, дальше информация крутится через разные системы, передается из уст в уста, хранится, агрегируется и т.д. Но в конечном итоге ее читает человек который может интерпретировать этот язык и получает мысль. Как именно формализованная мысль передается от одного узла к другому в описанной цепочке никого не по большому счету в итоге не волнует.
Если вы не знаете китайского языка – это вам не помешает сделать ctrl-c ctrl-v из одного места в другое.
Очень похожим образом работает RDF.
Информацию нужно интерпретировать только при ее формализации приложения в RDF и чтении ее агентом на другом конце. Между этими двумя этапами ее может обрабатывать кто угодно, как угодно ею обмениваться, не обязательно представляя какой смысл заложен, или понимая смысл, только часть утверждений.
Например, RDF утверждение (триплет субъект-предикат-объект)
Таким образом мы можем обмениваться с кем угодно, не делая лишних телодвижений, в том числе мы интегрироваться с n+1 системой делая больше усилий не больше чем мы для показа нашего веб-сайта n+1 пользователю! Не надо программировать ничего для этого. Все понятия которые нужны будут этой системе от вашей - она сможет получить и интерпретировать.
Для сравнения сегодня – надо поля одной системы явно связывать с другой (часто с каждой) с помощью XML, XSLT – или полями, получаемыми из API – и многие из нас знают какая, это головная боль.
Мы подошли к пониманию, что данные могут быть независимы от модели любого конкретного приложения. Т.е. набор фактов живет сам по себе. Мы можем их добавлять, удалять, делать к ним запросы, интерпретировать – но они логически независимы.
Этот факт несет следующее важное преимущество – легкость в изменении модели .
Представим, что потребуется сделать в приложении, которое опирается на реляционную модель. Для драматичности представим что делать это надо уже после запуска если требуется изменить модель данных, например, связать с объектом пользователя некую новую сущность, скажем адрес (который к слову, не одна строчка, а содержит отдельные поля для дома, города, улицы и т.д.). Что потребуется сделать с базой данных? Правильно подправить пару табличек, может быть создать новые, добавить связь между ними, изменить процедурки для доступа к данным, подправить веб сервис и все готово. Ну и конечно надо изменить пользовательский интерфейс.
Немного некомфортно этим заниматься, не кажется?
А на сколько проще было бы, если все, что надо было сделать – это только добавить пару полей в интерфейс и выполнить действие добавления одного нового утверждения для каждого нового поля (от этого минимума тоже можно иногда уйти, если у нас более универсально спроектирован интерфейс)? пара строчек кода…
С RDF моделью за спиной эта операция будет выглядеть именно так. Ведь все что хранится - это огромное число утверждений субъект-предикат-объект. Таким образом изменение модели данных перестает быть тем, что портит настроение как только об этом подумаешь, не правда ли здорово?
Editor’s Note: This presentation was given by Jesús Barrasa at GraphConnect San Francisco in October 2016.
Presentation Summary
Resource Description Framework (RDF) triple stores and labeled property graphs both provide ways to explore and graphically depict connected data. But the two are very different – and each have different strengths in different use cases.In this presentation, Dr. Jesús Barrasa starts with a brief , including the origins of the Semantic Web.
A Brief History: The RDF and Labeled Property Graph
Let’s go over a brief history on where these two models come from. RDF stands for Resource Description Framework and it’s a W3C standard for data exchange in the Web. It’s an exchange model that represents data as a graph, which is the main point in common with the Neo4j property graph.It understands the world in terms of connected entities, and it became very popular at the beginning of the century with the article the Semantic Web published in Scientific American by Tim Berners-Lee, Jim Hendler and Ora Lassila. They described their vision of the Internet, where people would publish data in a structured format with well-defined semantics in a way that agents - software - would be able to consume and do clever things with.
Next, persisting RDF - storing it - became a thing, and these stores were called triple stores . Next they were called quad stores and included information about context and named graphs, then RDF stores, and most recently they call themselves “semantic graph database.”
So what do they mean by the name “semantic graph database,” and how does it relate to Neo4j?
The labeled property graph, on the other hand, was developed more or less at the same time by a group of Swedish engineers. They were developing a ECM system in which they decided to model and store data as a graph.
The motivation was not so much about exchanging or publishing data; they were more interested in efficient storage that would allow for fast querying and fast traversals across connected data. They liked this way of representing data in a way that’s close to our logical model - the way we draw a domain on the whiteboard.
Ultimately, they thought this had value outside the ECM they were developing and a few years later their work became Neo4j.
The RDF and Labeled Property Graph Models
Now, taking into account the origin of both things - the RDF model is more about data exchange and the labeled property graph is purely about storage and querying - let’s take a look at the two models they implement. By now you all know that a graph is formed of two components: vertices and the edges that connect them. So how do these two appear in both models?In a labeled property graph, vertices are called nodes, which have a uniquely identifiable ID and a set of key-value pairs, or properties, that characterize them. In the same way, edges, or connections between nodes – which we call relationships - have an ID. It’s important that we can identify them uniquely, and they also have a type and a set of key value of pairs - or properties that characterize the connections.
The important thing to remember here is that both the nodes and relationships have an internal structure, which differentiates this model from the RDF model. By internal structure I mean this set of key-value pairs that describe them.
On the other hand, in the RDF model, vertices can be two things. At the core of RDF is this notion of a triple, which is a statement composed of three elements that represent two vertices connected by an edge. It’s called subject-predicate-object . Subject will be a resource, or a node in the graph. The predicate will represent an edge – a relationship - and the object will be another node or a literal value. But here, from the point of view of the graph, that’s going to be another vertex:

The interesting thing to know is that resources (vertices/nodes) and relationships (edges) are identified by a URI, which is a unique identifier. This means that neither nodes nor edges have an internal structure; they are purely a unique label. That’s one of the main differences between RDF and labeled property graphs.
Let’s take a look at an example to make this a bit more clear:
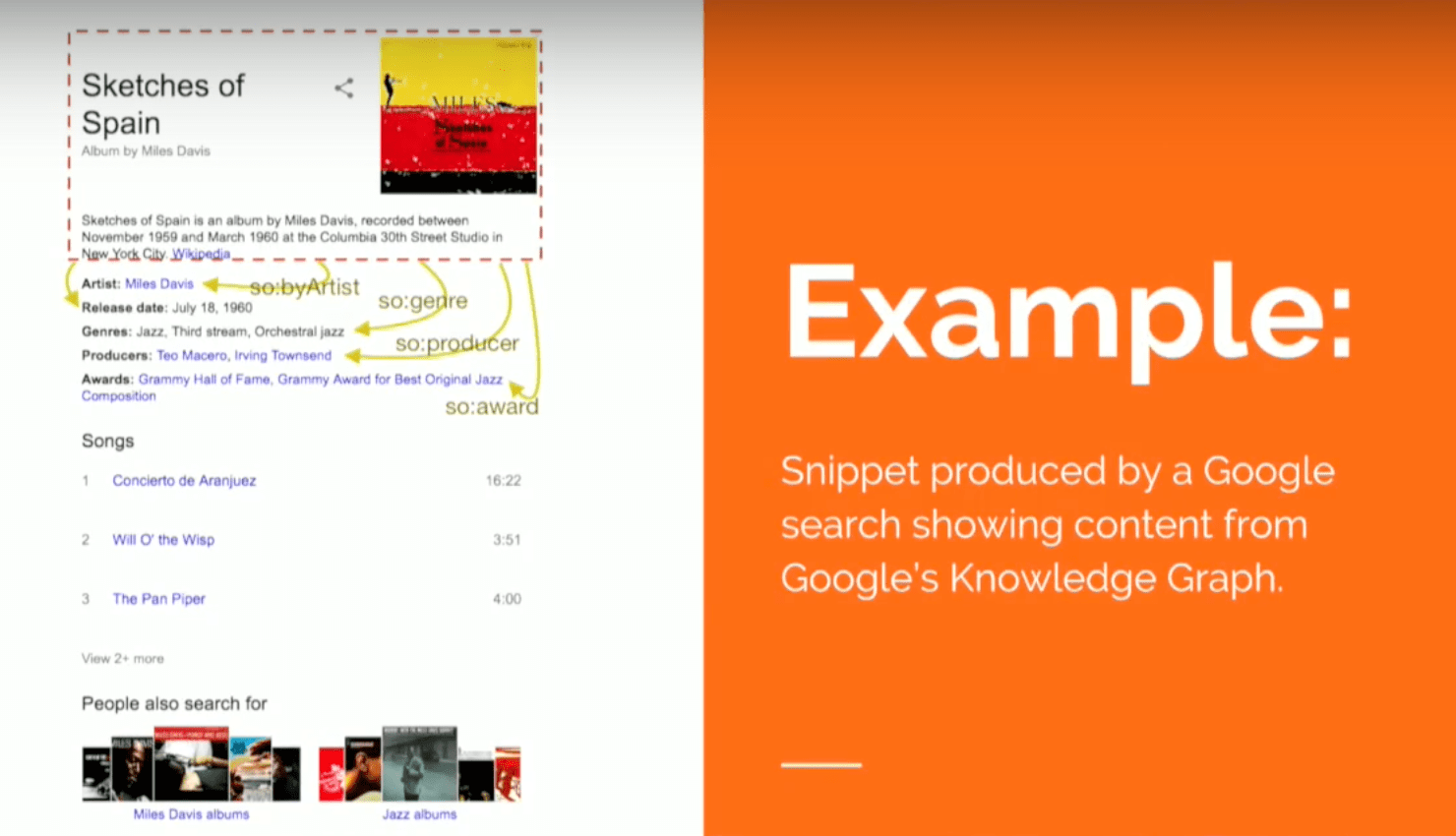
Here’s a rich snippets that Google returns when you do a search for Sketches of Spain , which is one of my favorite albums by Miles Davis. This search returns a description of the album with things like the artist, the release date, the genre, producers and some awards. I’m going to represent this information in both models below.
Below is one of the possible serializations of RDF called Turtle syntax:

You can see that the triples are identified by a URI, which is the subject. The predicate is the name and the object will be Sketches of Spain , which together is a sequence of triples. So these are the kinds of things you will have to write if you want to insert data in a triple store.
Let’s look at how this information is displayed graphically:
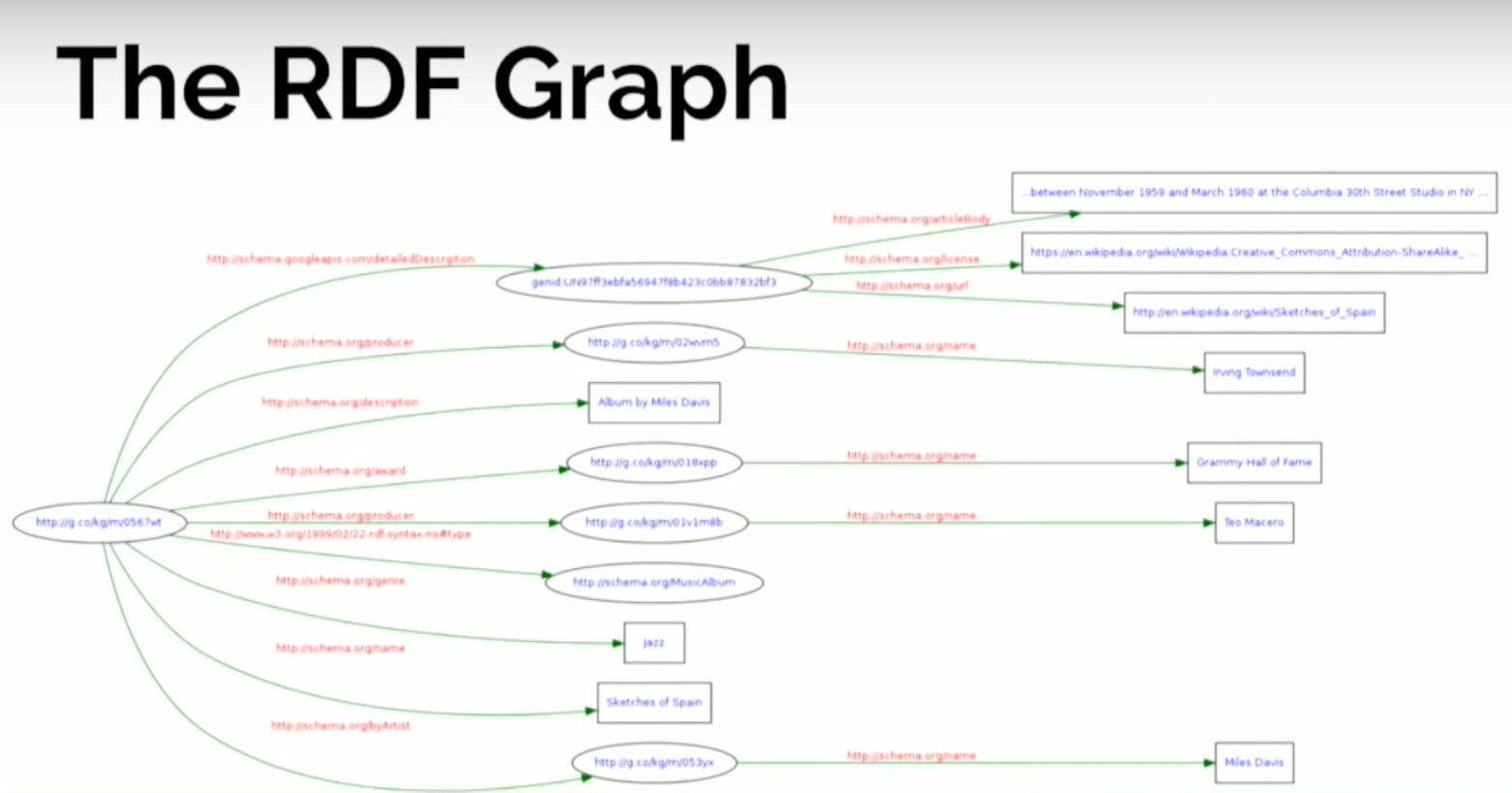
The nodes on the left represent the album, which has a set of edges coming out of it. The rectangles represent literal values - the description: album about Miles Davis, the genre, the title - and it has connections to other things that are in ellipses that represent other resources (i.e., other nodes in the graph) that have their own properties and attributes.
What this means is that by representing data in RDF with triples, we’re kind of breaking it down to the maximum. We’re doing a complete atomic decomposition of our data, and we end up finding nodes in the graph that are resources and also literal values.
Now let’s look at it from the point of view of the labeled property graph. What I’ve created below is a sequence of statements that contain exactly the same information as the Turtle syntax above:

The semantics are the same. There’s no standard serialization format, or a way of expressing a labeled property graph, but rather a sequence of CREATE statements do the job here.
We create a node, which is more obviously represented with a parenthesis, and then the attributes - or the internal structure - in the curly bracket: the name, the description and the genre. Likewise, the connections between nodes are described with hard brackets.
Below is what the labeled property graph looks like:

The first impression is that it’s much more compact. Even though it has certain elements in common with the RDF graph, it’s completely different because nodes have this internal structure and values of attributes don’t represent vertices in the graph.
This allows for a much more reduced structure. But we still have the album at the center, which is connected to a number of entities, but the title, name and description aren’t represented by separate nodes. That’s a first distinction.
Sometimes there’s confusion when we compare the two models. If you have a graph with two billion triples, how do the two compare in terms of nodes, for example? If we take a graph with n nodes with five properties per node, five attributes, five relationships and five connections, we would get 11 triples per node in a labeled property graph.
Again, I’m not comparing storage capacity, but keep in mind that when you have a 100 million triple graph (i.e., RDF graph), that’s an order of magnitude bigger than a labeled property graph. That same data will probably be equivalent to a ten-million-node labeled property graph.
Key Differences Between RDF and Property Graphs
Difference #1: RDF Does Not Uniquely Identify Instances of Relationships of the Same Type
Now that we know a bit more about the two models, let’s compare differences in terms of exclusivity.The first one is quite important, and that is the fact that in RDF it’s not possible to uniquely identify instances of a relationship. In other words, we can say: it’s not possible to have connections of the same type between the same pair of nodes because that would represent exactly the same triple, with no extra information.
Let’s look at the following as an example, a labeled property graph and an RDF graph in which Dan cannot like Ann three times; he can only do it once:

We create a node called Dan that LIKES Anne . I repeat that Dan likes Anne two more times, and I end up with a graph that has three connections of type LIKES between Dan and Ann. Good.
Not only can we visualize this in a helpful way, but we can also query it to ask, “How many times does this pattern appear in the graph?” which returns a count of three.
Now let’s try to do the same in RDF using SPARQL:

What insert a statement that says Dan has name Dan, Ann has name Ann and Dan LIKES Ann, which we repeat three times. But see the graph that we get instead (above).
We have the values of the properties as vertices of the graph, and we have Dan with name Dan. We have Ann with name Ann, and we have a single connection between them, which is sad, because Dan liked her three times.
If I do the count again searching for this particular triple pattern, and I do the count, I get one. The reason for that is it’s not possible to identify unique instances of relationships of the same type with an RDF triple store.
Difference #2: Inability to Qualify Instances of Relationships
Second, because you can’t identify these unique instances in RDF, you cannot qualify them or give them attributes. Let’s take a look at another example that explores flights between New York City and San Francisco:
It costs $300 and is a total of 4,100 kilometers. Again, this statement can be expressed in Neo4j’s graph query language, Cypher, saying that there’s a connection between New York City and San Francisco, and that the connection has two attributes: the distance and the cost in dollars.
We produce a nice graph and can query the cost and distance of the connection to return two nodes.
If I try to do the same in RDF, I encounter a problem:

In this query, we say there’s a city called New York, a city called San Francisco, and a connection between them.
But how do I state the fact that this connection has a cost? I could try to say something like, “Connection has a distance.” But which connection? That would be a global property of the connection, so you can’t express that in RDF. As you can see above, here’s the graph that this type of SPARQL query produces.
RDF Workarounds
There are a few alternatives for these weaknesses in RDF.One of them is a data modeling workaround, but we’re going to see that this is the same problem we experience with a . What happens when we have these many-to-many relationships - people knowing people, and people being known by others? This provides an entity-relationship model, but then you have to translate this into tables with several JOINs.
Because the modeling paradigm doesn’t offer you a way to modeling these types of relationships, you have to use what you have on hand and represent it the way you can. And as you know, the problem is that this starts building a gap between your model as you conceive it, and the model that you store and query. There are two alternate technical approaches to this problem: reification and singleton property.
Below is one RDF data modeling workaround, which is the simple option:

Because in RDF we don’t have attributes in relationships, we create an intermediate node. On the left is what I can do in the labeled property graph. Because we can’t create such a simple model in RDF, we create an entity that represents the connection between New York and San Francisco.
Once I have that node, I can get properties out of it. This alternative isn’t too bad; the query will be more complicated, but okay.
Now let’s take a look at reification, which - as you can see - isn’t very readable:

We still have Dan with with name Dan , and Ann with name Ann with a connection saying that he likes her.
With reification, we create a metagraph on top of our graph that represents the statement that we have here. We create a new node that represents a statement and points at the subject Dan, at the object Ann, and at the property stating the fact that he likes her. Now that I have an object - a node - I can add a counter, which tells us three.
This is quite ugly. On the one hand, you can still query who Ann likes:

But if you want to query “how many times,” you have to go look at both the graph and the metagraph. So if Dan likes Ann, then look at the statement that connects Dan and Ann and get the counter.
Now, imagine if you need to update that. You would have to say, “Dan has liked her one more time.” You wouldn’t come and say, “Add one more” because that doesn’t add more information. You will have to come and say, “Grab a pattern, take the value in the counter, increase it by one, and then set the new value.”
The Singleton property is another modeling alternative pretty much in the same vein:

You have your original model - Dan with his name who likes Ann, with her name. You can give this relationship a unique name, ID1234 , which allows us to describe it. We can say it’s an instance of likes and I can give it a counter of three.
Again, I’m building a metamodel that - while more compact than the reification model - still doesn’t allow you to ask, “Who does Dan like?” You have to ask, “Who does Dan 1234 ?” which is the type like .
Difference #3: RDF Can Have Multivalued Properties and the Labeled Property Graph Can Have Arrays
In RDF you can have multi-value properties - triples where the subject and predicate are the same but the object is different - which is fine. In the labeled property graph you have to use arrays, which is the equivalent.
In the snippet we had before, we had an album that had two values for the genre property: jazz and orchestral jazz. That’s easy to express in triples, and in Cypher you will need to use an array - not too bad.
Difference #4: RDF Uses Quads for Named Graph Definition
Another difference is this notion of quad, which has no equivalent in labeled property graphs. You can add context or extra values to triples that identifies them and makes it easy to define subgraphs, or named properties.We can state that Dan likes Ann in graph one and Ann likes Emma in another graph:

RDF & Labeled Property Graph Query Languages
The two different models also rely on different database query languages.Because of the atomic decomposition of the data and RDF, you typically have longer patterns when you perform queries. Below is a query that has the names of artists with albums produced by Irving Thompson:

You have four patterns, each of which represents each of the edges in the more compact labeled property graph. But this isn’t what I would call an essential differentiator.
There were a few recent updates to both the SPARQL and Cypher query languages:

Something like uppercasing the values of a property in Cypher is very SQL-like and simple.
You can much a person and attribute name to uppercase , whereas in SPARQL you will have to MATCH it, BIND it to a variable, do the uppercase , and then do the insertion and the deletion because we can have multiple values. So by updating you need to delete the previous value, unless you want to keep both of them.
RDF & Labeled Property Graph Data Stores
RDF stores are very strongly index-based, while Neo4j is navigational. It implements index-free adjacency, which means that it stores the connections between connected entities, between connected nodes, in disks.This means that when you query Neo4j, you’re actually chasing pointers instead of scanning indexes. We know that index-based storage is okay for queries that aren’t very deep, but it’s very difficult to do something like path analysis. Compare that to Neo4j, which allows you to have native graph storage that is best for deep or variable-length traversals and path queries.
It’s fair to say that triple stores were never meant to be used in operational and transactional use cases. They should be used in mostly additive, typically slow-changing - if not immutable - datasets. For example, the capital of Spain is Madrid, which isn’t likely to change. Conversely, Neo4j excels in highly dynamic scenarios and transactional use cases where data integrity is key.
A Comparison: Semantics

The first two lines are on the front end of RDF in total notation, saying that John Smith lives in London and that London is a city in England. The second one is a fragment of JSON that could easily represent the same information. The third one is JSON-LD and includes both the data and the ontology, and the final one is a fragment of Cypher.
Semantics can mean two things in the RDF world. The first is the idea of vocabulary-based semantics. Because you can identify relationships with URIs, you can define agreed-upon vocabularies like Schema.org and Google Knowledge Graph (GKG) . This covers most of the usage of RDF today.
The other meaning is inference-based semantics, which is rule-based - including OWL. We use this when we want to express what the data means so that I can infer facts, do some reasoning or check the consistency of the dataset.
Let’s look at a couple examples. The first example provides a simple pair of facts: John lives in London. London is in England. You can express this with two RDF triples:
:JohnSmith:livesIn:London:London:locationIn:England
Now you run a query: who lives in England? You can express that in SPARQL:
SELECT ?who
WHERE { ?who:livesIn:England }
But it returns zero results because you have to say:
X:livesIn ?city ^
?city:cityIn ?ctry
=> ?x:LivesIn ?ctry
If someone lives in a city and the city is in a country, then you live in the country. But no one’s going to figure that out if you don’t make it explicit in a rule, and this is an example of how you have to make the semantic explicit. The real question is: are your semantics explicit?
If we ask the question again, now that we have defined our rule, it will return John Smith.
Below is another example that shows importing data from two data sources into a triple store. There are two facts coming from datasource1: Jane Smith’s email is [email protected], and her Twitter handle is @jsmith. This can look like the following two triples:
:JaneS1:hasEmail "[email protected]"
:JaneS1:hasTwitterHandle "@jsmith"
Now we get another pair of triples from another data source that says: Jane Smith’s email is [email protected] and her LinkedIn profile is “http://linkdn.com/js.” Again, the two triples below look like this:
:js2:hasEmail "[email protected]"
:js2:hasLnkdnProfile "http://linkdn.com/js"
Next you put it into the RDF graph thinking that semantics are going to do the magic. You ask the question: What’s the LinkedIn profile of the person tweeting as @jsmith? The SPARQL query looks like this:
SELECT ?profile
WHERE { :hasTwitterHandle "@jsmith" ; :hasLnkdnProfile ?profile . }
But again you get no results, because - like in the previous case - you have to say that the email address is a unique identifier and therefore you can infer that if two resources have the same email, you can derive that they’re the same and can be expressed with a rule like this one:
X:hasEmail ?email ^
?y:hasEmail ?email
=> ?x owl:sameAs ?y
You can also express this more elegantly in OWL, which would look like this:
:hasEmail rdf:type
owl:InverseFunctionalProperty
?prop a owl:InverseFunctionalProperty ?p^
?x ?p ?al
=> owl:sameAs ?y
An inverse functional property is a primary-key-style property. It’s not exactly the same because a primary key is a kind of constraint that would prevent you from adding data to your database if there’s another one with the same value.
Here, you can add data without any problem. But if we find two that have the same value, we’re going to think that these two are the same.
Even if we express this in a more declarative way, these are the semantics of an inverse functional property. Basically if two values have the same value, I can derive that they are the same. We re-run the query and this time it will return Jane Smith’s LinkedIn profile.
It’s all about making the data explicit. There’s really no magic here; RDF is just a way of making data more intelligent and making your semantics explicit. Below is a quote from Tim Burners-Lee that speaks to this:

A Demo: How Do We Get to a Semantic Graph Database?
I’m going to show features and capabilities in Neo4j that are typically from RDF as stored procedures and extensions. Hopefully, they’ll make their way into the APOC library soon.So what are the takeaways from this demo? The first one was mentioned in the presentation by the Financial Times, an organization that made the transition from RDF to a labeled property graph.
They thought they needed a linked semantic data platform to connect their data, but what they actually needed was a graph. So always ask yourself what kind of features you need. Is it about the inferencing? Is it about semantics? Or is it just a graph?
If you store your data in RDF and query it in SPARQL, you’re not semantic - you have a graph. In most of the use cases, you find yourself not using as much of OWL and all the semantic capabilities as you would, because you know it’s extremely complex and it results in performance issues. If you’re working with a reasonably-sized dataset, don’t expect it to finish the query.
We also know that publishing RDF out of Neo4j is trivial, which is the same with importing RDF. The code is under 100 lines and is available on Github . It’s a really simple task.
And I’ve also shown that inference doesn’t require OWL. In the end, semantics (inference) is just data-driven, server-side logic, typically implemented as rules. You’re putting some intelligence close to your data that’s in turn driven by an ontology. And if you manage to balance expressivity and performance without falling into unneeded complexity, then it may be a useful tool.
I’m not going to criticize OWL because its own creators discuss why it’s not being adopted. It’s definitely not taking off, and I think one of the reasons is because it can be overkill for many use cases.

